Getting started with Apache Spark
Lee Hawthorn May 29, 2019 #Spark #PythonIn this post I will show you how to get started with Apache Spark with Python on Windows. This post is the first in a series of 3 that is focussed on getting Spark running.
In case you are wondering what Apache Spark is, I can tell you it's a unified analytics engine for large-scale data processing.
You can run queries using Python/Scala/Java/R/SQL against a diverse range of big data sources i.e Hadoop. Apache Spark manages the magic to run the job on a cluster of machines to take advantage of parallel processing.
Here are the steps I used to get it running on my Windows 10 laptop, note, you can follow my folder suggestions or use your own.
Download
- Java8 SDK, make sure to install in a folder with no space. I installed in c:\Java
- Apache Spark - I used Apache Spark pre-built for Hadoop 2.7 or later. Install this to c:\spark.
- Install Python3 if you don't already have it. Check this runs from the command prompt too if installing for the first time.
- You need a Hadoop emulator in the absence of a real Hadoop cluster. Install WinUtils.exe from Github - this will make Spark play nicely in the absence of a Hadoop source. Install this file to c:\winutils\bin
Config
- Create the folder D:\tmp\hive
- Run a command prompt with elevated permissions and run
cmd> c:\winutils\bin\winutils.exe chmod -R 777 D:\tmp\hive - Set up user environment variables :
JAVA_HOME c:\Java SPARK_HOME c:\Spark HADOOP_HOME c:\winutils
-
Add to your path :
%SPARK_HOME%\binand%JAVA_HOME%\bin -
Change logging by renaming c:\spark\config\log4j.properties.template to : log4j.properties. Open this file and change the line
log4j.rootCategory=WARNto :log4j.rootCategory=ERRORThis will keep the logs cleaner.
Test Install
Open up a command prompt and run
pyspark
A python shell should open. Check for the Spark text.
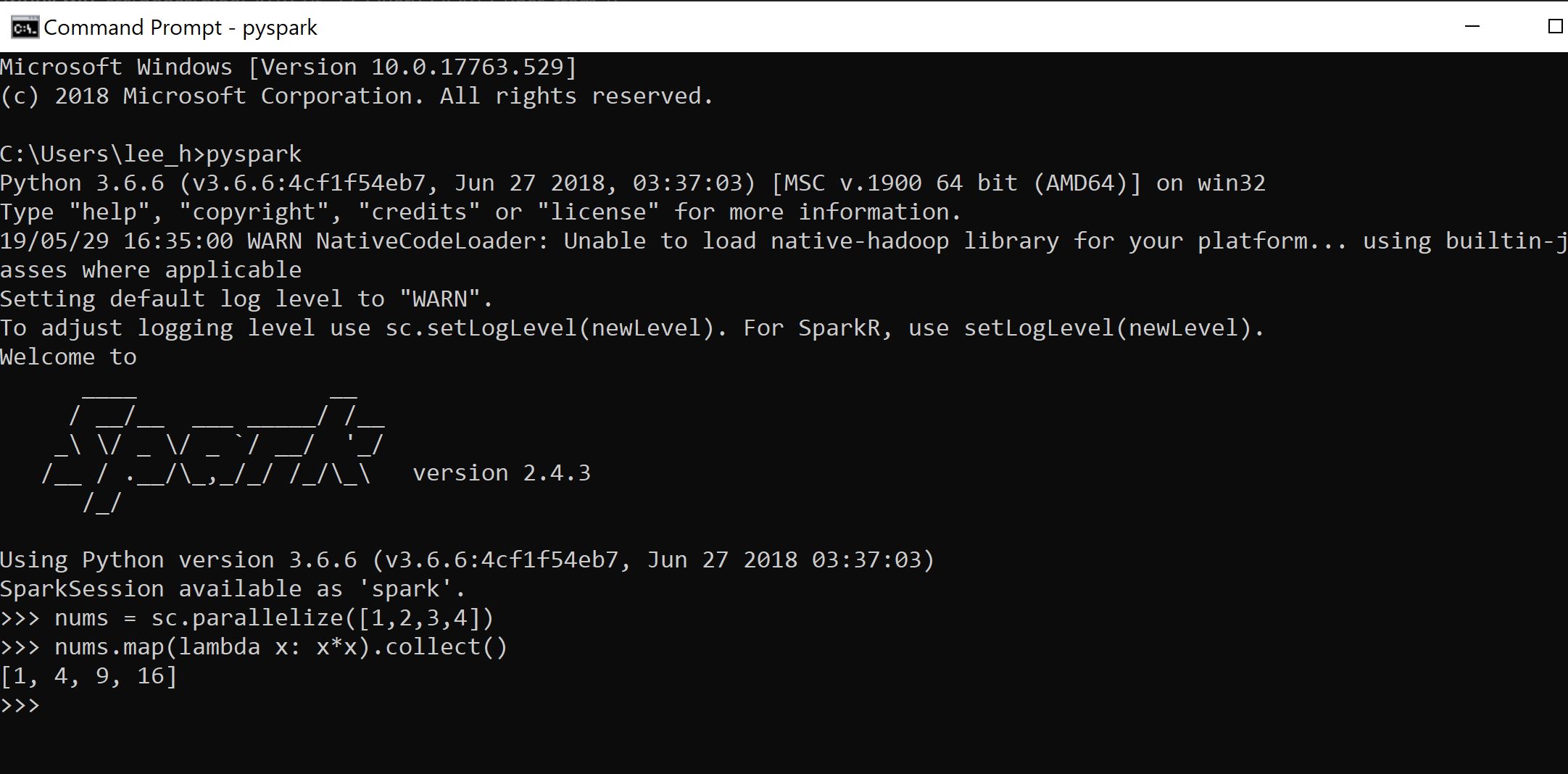
The Hello World for Spark is the square root test below
nums = sc.parallelize([1,2,3,4]) nums.map(lambda x: x*x).collect()
If you get the result as per below you're good to go.
In the next post I will show you how to install a sample database and run a real query.