Scraping Open Table data with Selenium and Beautiful Soup
Lee Hawthorn September 16, 2020 #PythonIn this article we'll scrape data from Open Table for restaurants in Liverpool.
As Open Table uses JavaScript to produce pages we need to use Selenium.
I'm using Ubuntu 20.04 for this code.
Assuming you already have Python 3 installed.
Here are the other install steps:
- Download and Install the Firefox Geckodriver by running these commands in your terminal.
#!/usr/bin/env bash # get latest - https://github.com/mozilla/geckodriver/releases wget https://github.com/mozilla/geckodriver/releases/download/v0.23.0/geckodriver-v0.23.0-linux64.tar.gz tar -xvzf geckodriver-* chmod +x geckodriver sudo mv geckodriver /usr/local/bin/
- Install additional packages if you don't already have them.
pip install selenium pip install beautifulsoup4 pip install pandas
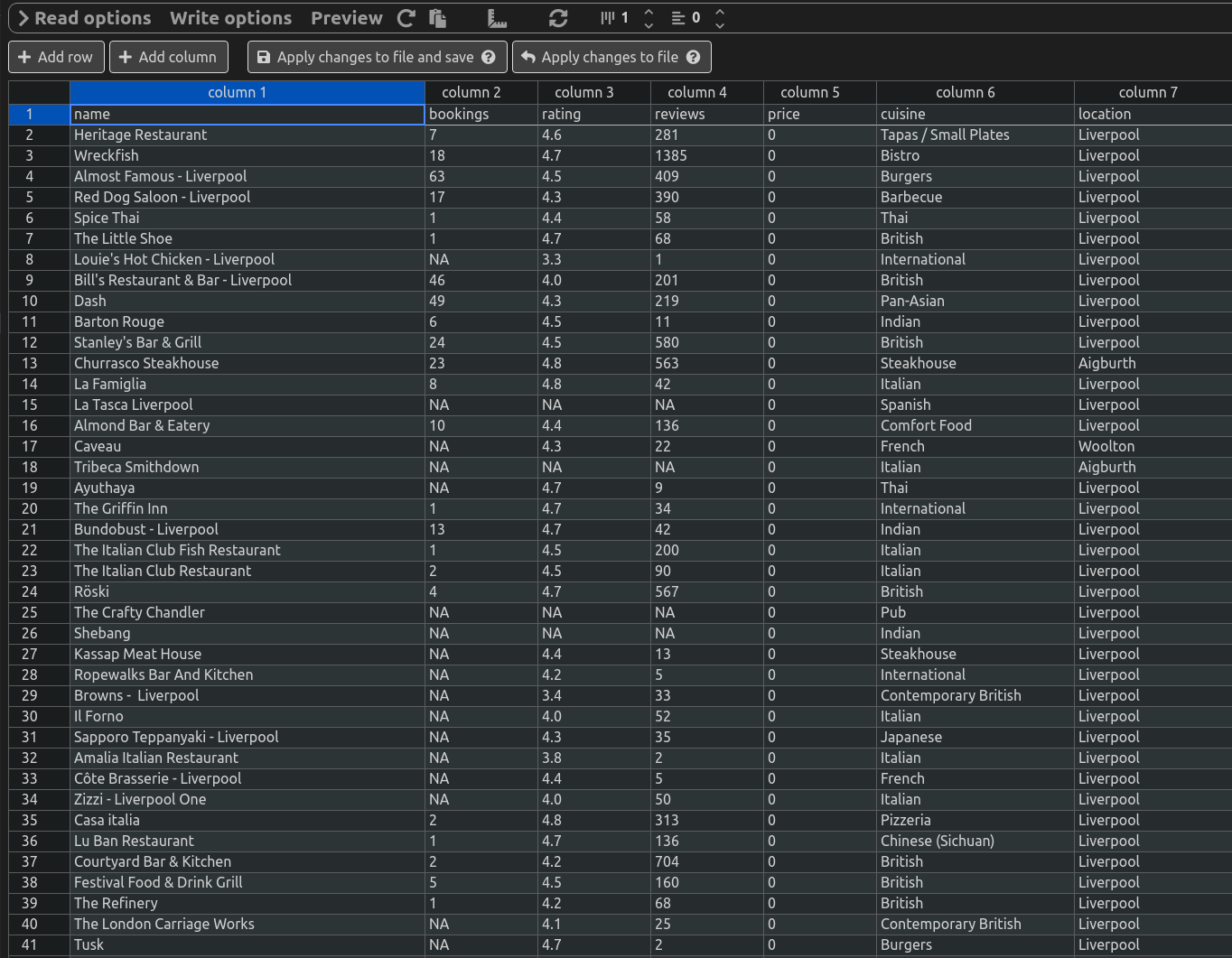
Open Table is a good source of restaurant info. We can see restaurant details like bookings, reviews, cuisine.
We need to browse to the 'listing' page for a specific area.
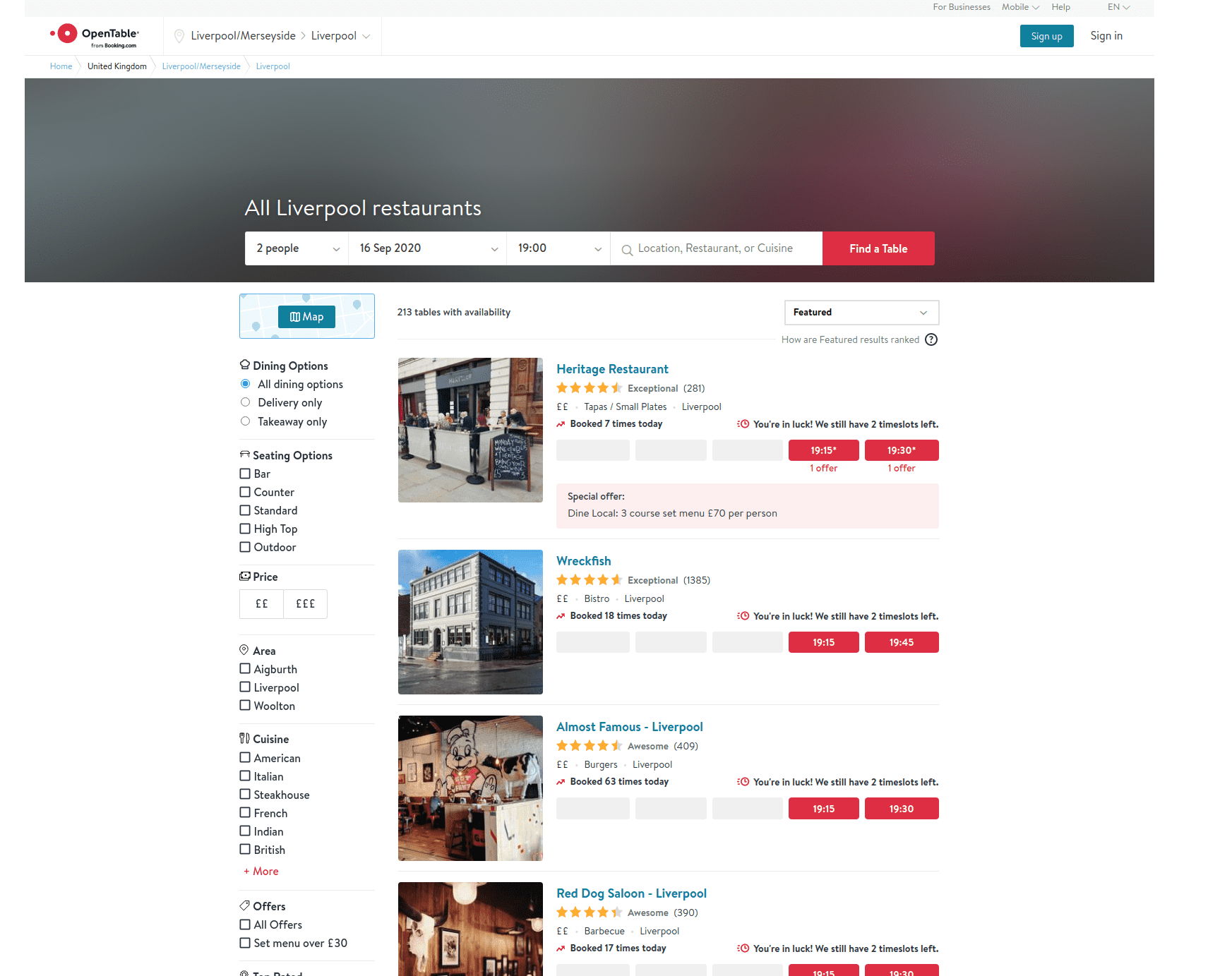
We can scrape data off each page using a combination of Selenium to navigate the site and Beautiful Soup to parse the page.
The page parser is a little complex as we need to use regex to extract booking number and review count from the spans. We also need to check each field, returning NA when no value is found.
Note, this code needs to be maintained as the site changes, hence, it may not work when you're reading this post.
import re from time import sleep import pandas as pd from bs4 import BeautifulSoup from selenium import webdriver def parse_html(html): """Parse content from various tags from OpenTable restaurants listing""" data, item = pd.DataFrame(), {} soup = BeautifulSoup(html, 'lxml') for i, resto in enumerate(soup.find_all('div', class_='rest-row-info')): item['name'] = resto.find('span', class_='rest-row-name-text').text booking = resto.find('div', class_='booking') item['bookings'] = re.search('\d+', booking.text).group() if booking else 'NA' rating = resto.find('div', class_='star-rating-score') item['rating'] = float(rating['aria-label'].split()[0]) if rating else 'NA' reviews = resto.find('span', class_='underline-hover') item['reviews'] = int(re.search('\d+', reviews.text).group()) if reviews else 'NA' item['price'] = int(resto.find('div', class_='rest-row-pricing').find('i').text.count('$')) item['cuisine'] = resto.find('span', class_='rest-row-meta--cuisine rest-row-meta-text sfx1388addContent').text item['location'] = resto.find('span', class_='rest-row-meta--location rest-row-meta-text sfx1388addContent').text data[i] = pd.Series(item) return data.T
The only other task is to use Selenium to click through the pages, downloading each one. This isn't overly complex. We're just clicking the next page and counting the pages as we go. Note, we're adding the header by checking for the first page. I added a try/except as the last page doesn't have a Next button to click.
# store Liverpool restuarant results by iteratively appending to csv file from each page driver = webdriver.Firefox() url ="https://www.opentable.co.uk/liverpool-restaurant-listings" driver.get(url) page = collected = 0 x = True while x == True: sleep(1) new_data = parse_html(driver.page_source) if new_data.empty: break if page == 0: new_data.to_csv('results.csv', index=False) elif page > 0: new_data.to_csv('results.csv', index=False, header=None, mode='a') page += 1 collected += len(new_data) print(f'Page: {page} | Downloaded: {collected}') try: driver.find_element_by_link_text('Next').click() except: print("End") x=False driver.close() restaurants = pd.read_csv('results.csv') print(restaurants)
Here's some data from the CSV file.