Scraping data with R
Lee Hawthorn January 01, 2016 #RWeb Scraping is used to pull data from web pages when an API is unavailable. Imagine copying the data by hand (horrible chore) this is essentially web scraping.
I’ve wanted to get my head around this for a while and see if modern sites are structured in ways to make this easier.
When I was researching wine types for another project an opportunity came up.
Data Source
Wine.com has a stellar dataset and they actually have a good API but I’ll ignore that for this demo.
The packages we can use to make our life easier are:
rvest – this is from Hadley Wikham and makes scraping web data simple.
stringi – this comes from Marek Gagolewski, Bartek Tartanus et al and gives us many functions to manipulate text from any locale. In Excel we have functions like Trim(), Left(), Right(), Mid() – well, after reading the docs for stringi my mind was truly blown.
There’s one other tool that’s recommended, Selectorgadget this allows to easily select objects on a web page using CSS or Xpath.
The first thing to do when scraping a page is to browse to the page.
http://www.wine.com/v6/wineshop/list.aspx?N=7155+2096&pagelength=25
We can then use the Selectorgadget tool to detect the right CSS selector. In the screenshot below I’ve clicked over the abstract and the class .productAbstract has been selected. We know it’s the right selector as the other items in the list are highlighted. A little patience is required here as there can be different selectors in the CSS which can give erroneous data.
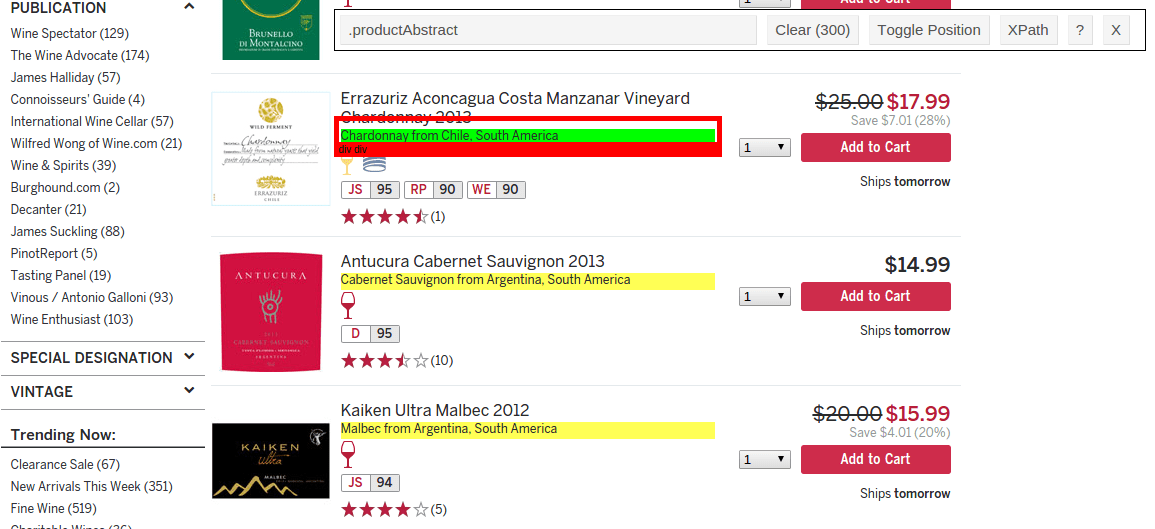
The other selector we need is .productList.
With this information we’re good to go.
The script starts with loading the libraries and setting the URL we found earlier. I’ve increased the pagelength for illustration purposes.
library(rvest) library(stringi) url <- "http://www.wine.com/v6/wineshop/list.aspx?N=7155+2096&pagelength=100"
To pull the web page into R’s memory we simply use page <- html(url)
We can then use the selector we found earlier to extract the data.
product_name <- page %>% html_nodes(".listProductName") %>% html_text()
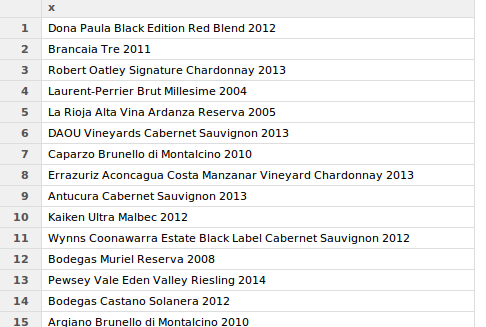
We can do a similar thing to extract the Abstract.
abstract <-page %>% html_nodes(".productAbstract") %>% html_text()

That is not helpful at all. We have \r\n and too much space. Fear not, we can use stringi to clean up the data. When I look at a problem like this I breakdown the problem into smaller bits and solve these individually. So in this spirit we’ll handle the \r\n problem first.
stri_replace_all_regex(abstract, "\r\n", "")
This is simply replacing the string “\r\n” with empty. Of course with Regex there are many ways to skin a cat. If you want to learn more feel free.
We have spaces left to eliminate. Notice I’m searching for double space as I don’t want to remove the space from the abstract itself.
stri_replace_all_regex(" ","")
We add the product and abstract columns together, add columns names and export to CSV. Job done.
products <- cbind(product_name,abstract) colnames(products) <- c("ProductName", "Variety", "Origin") write.csv(products,file="Product.csv")
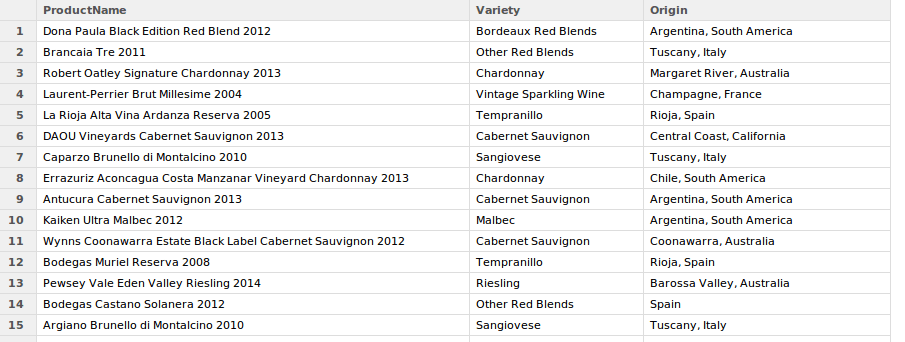
The complete code is listed below
library(rvest) library(stringi) url < -"http://www.wine.com/v6/wineshop/list.aspx?N=7155+2096&pagelength=300" page <- html(url) product_name <- page %>% html_nodes(".listProductName") %>% html_text() abstract <- page %>% html_nodes(".productAbstract") %>% html_text() abstract <-(stri_replace_all_regex(abstract, "\r\n", "") %>% stri_replace_all_regex(" ","") %>% stri_split_fixed(" from ", simplify = TRUE)) products <- cbind(product_name,abstract) colnames(products) <- c("ProductName", "Variety", "Origin") write.csv(products,file="Product.csv")